
We had a dream...
TeleportHQ was founded in 2016 with the mission to humanize technology. We assembled a team of international designers, developers and data-scientists driven to build tools powerful enough to hold and leverage human accumulated knowledge and thus increasingly automate the process of user interface building.
One of our initial research wish list ideas was to generate websites simply by talking to a computer. Recent breakthroughs in AI made UI generation tangible for the first time.
In order to build a successful machine learning solution, we needed two primary elements: a large sum of data, and a “human-to-computer translator” tool which would recognize natural language and convert it into computer code languages. The translator tool in particular was proving very difficult to identify. We tried using tools like IBM Watson or Google Dialogflow, but they proved unsuitable for our purposes.
At the same time, our engineering team was building the Playground, a new visual development platform for user interfaces. Playground’s technology eventually allowed developers, designers, and product makers to collaborate on a project, and to instantly see the resulting code of their collective work in real-time.
Playground took off, gathering strength and a growing user community. It is built on top of User Interface Development Language UIDL, TeleportHQ’s intermediary representation language, and a set of open-source code-generators.
You can see how they work together in our REPL, where you can edit the UIDL and see code generated in real time in different javascript flavors.
There was an additional benefit in creating Playground: its UIDL and open-source code generators provided the critical piece of infrastructure that liberated our initial research track. For a data-scientist, the UIDL as a domain-specific language was much easier to work with than pure code, which can crash at the slightest syntax error and solicits human intervention to be repaired.
Thanks to this benefit, TeleportHQ has been making significant advancement in the quest to generate websites by talking to a computer. Here's a video with our latest progress:
We are on the verge of making our dream a reality, and we’d like to share some of the crucial steps of our research in the following blog post.
Setting the Goal: Defining the output of the model
Our first step was to define the output for which we would train our model. In order to simplify the problem, we chose what we like to call a “semantic” approach, meaning a set of bounding boxes with their types and their absolute positioning. We named this format “low-fidelity design” as it is a subset of what is usually called a high-fidelity design (which also contains colors, shapes, font types, and other visual attributes). We could say that our low-fidelity design is to high-fidelity design what a structure of plain HTML tags is to a web page with all its texts and CSS properties.
Curating the Data: Constructing the training dataset
It is worth mentioning that parallel to our Playground development, we started to collect and curate millions of web pages, in order to give us a continuous and curated data supply which we used for our wireframe-to-code project.
In order to manipulate and access this growing database, we built a custom web parser capable of parsing up to 6 000 pages per minute. You can read more about this topic in this blogpost.
We decided to generate the webpages iteratively, starting with the navbar and finishing with the footer. To do so, we extracted from our main web pages dataset, a subset of 850 000 sections representing different semantic parts of the web pages. Check the below example:

Initial Attempts: Sequence to Sequence Autoencoder
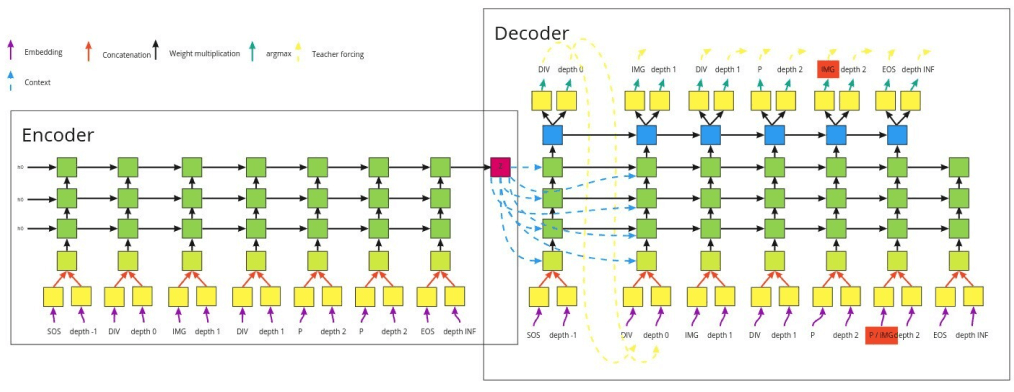
At the end of 2019, we started with a simple, unsupervised approach based on a sequence to sequence autoencoder. In the middle of this architecture, there is a bottleneck in which the sections are encoded into a one dimension array. This bottleneck is usually used to generate new data; therefore, we thought that it could then be possible to generate new designs from it by randomly sampling its values.
Unfortunately, it did not work as expected. Although the system could learn to encode and decode, it failed miserably on new samples or with a random encoding.
We tried a few other approaches and architectures including variational autoencoders, GANs and graph neural networks but after 9 months of trial and error, the results were not viable.
The Turning Point: Enter GPT-3 Technology
Earlier this year, OpenAI released a new iteration of Generative Pretrained Transformer (GPT-3). Their system sets the new standard in terms of state of the art results on a number of benchmarks such as question answering and machine translation.
GPT-3 generates sequences of discrete values based on a given context. Taking this context, the model will then generate the rest of the sequence by auto completing it token after token.
Because it was trained on the full internet, the model shows amazing results on a variety of problems, from philosophy to medicine. But one type of use case in particular caught our attention: the generation of code.
Two examples in particular stood out. In the first one, GPT-3 was used to generate bash commands. In the second one, it was used to generate JSX code. These two examples triggered an enthusiastic response from our team, as this model had obviously digested all of stackoverflow’s data with success. This was irrefutable proof that GPT technology could make it possible to talk to a machine and generate user interfaces.
Wind in the Sail: Harnessing the Power of GPT
Excited by the potential of this technology, TeleportHQ asked for early access to GPT-3; but our demand didn’t succeed. Nevertheless, we remained convinced that the answer to our machine learning problem lay with GPT architecture. This compelled us to build our own version. After some research, we chose to work with minGPT, a lightweight implementation of GPT.

Armed with our available data and the simplicity of minGPT, we were able to feed our data to the network very quickly. To our greatest surprise, it - just - worked.
In this first experiment, the model learned to generate our page sections character after character, including the depth and coordinate of each element.
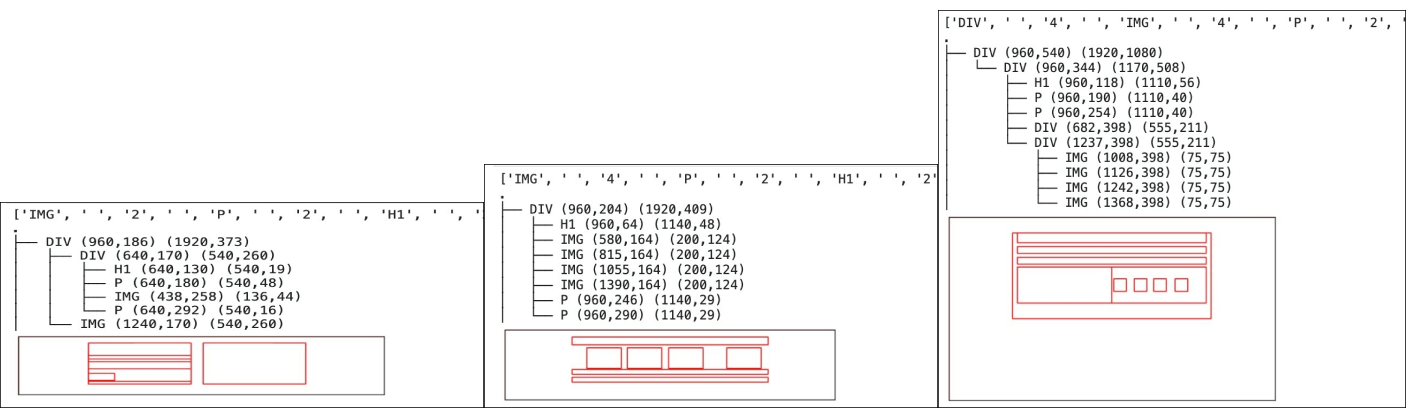
Using the context “DIV 0 0.5 0.5 1.0 1.0”, the model was able to auto-complete the data of a section. It was then possible to reconstruct the following tree view:

Although promising, the problem was not yet solved: the context could not yet be defined as user intent . We therefore refined the model by inserting the content to be generated (e.g. numbers of images, paragraphs or divs) at the beginning of the sequence.
Once again: it just worked.
Below we can see a few (cherry picked) sections generated by this improved model. In all cases, not only were the tree views and bounding boxes coherent, but the generated sections also contained the requested contents.
An example of the new context looks like this: “IMG 2 P 2 H1 2 $”. By simply inserting it before the section itself, the model could begin after the first “$” and auto-generate the entire section.
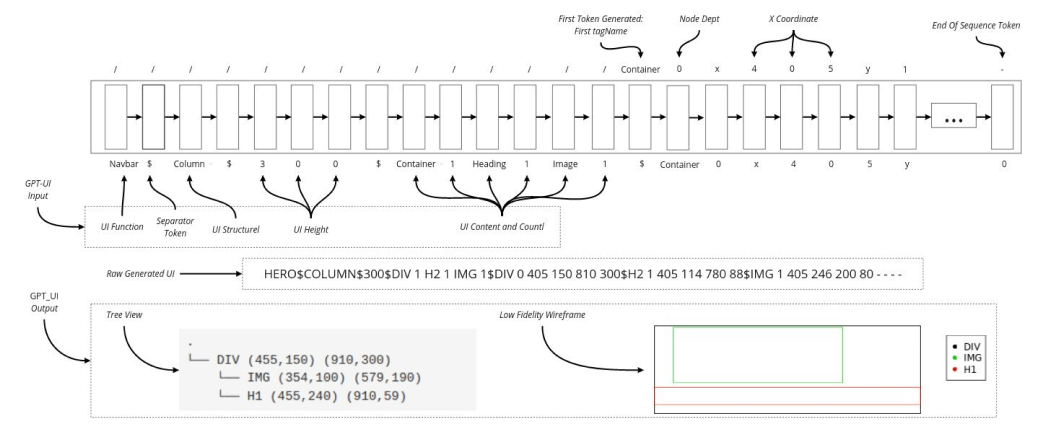
We then went even further by supplying additional information at the beginning of the sequence in order to enrich the prompt. The system could subsequently learn to generate sections of specific height, orientations, and functions.
We still needed one last element: a user interface in order for a human to communicate with the computer using natural language. We built the following setup, in which the user intent is supplied by a form.
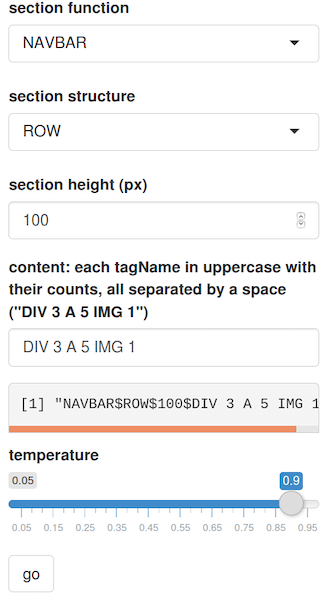
After constructing the form, we added a programmatic overlay that transformed the natural language commands (eg. “Hey TeleportHQ, build me a section of type navbar with 1 image and 4 links of height 65 pixels“) into contexts (eg. “NAVBAR $ h 65 $ IMAGE 1 LINK 4 $”).
Below you can see a demo of our current user interface. It allows the user to interact with the model and create a website page in just a few minutes.
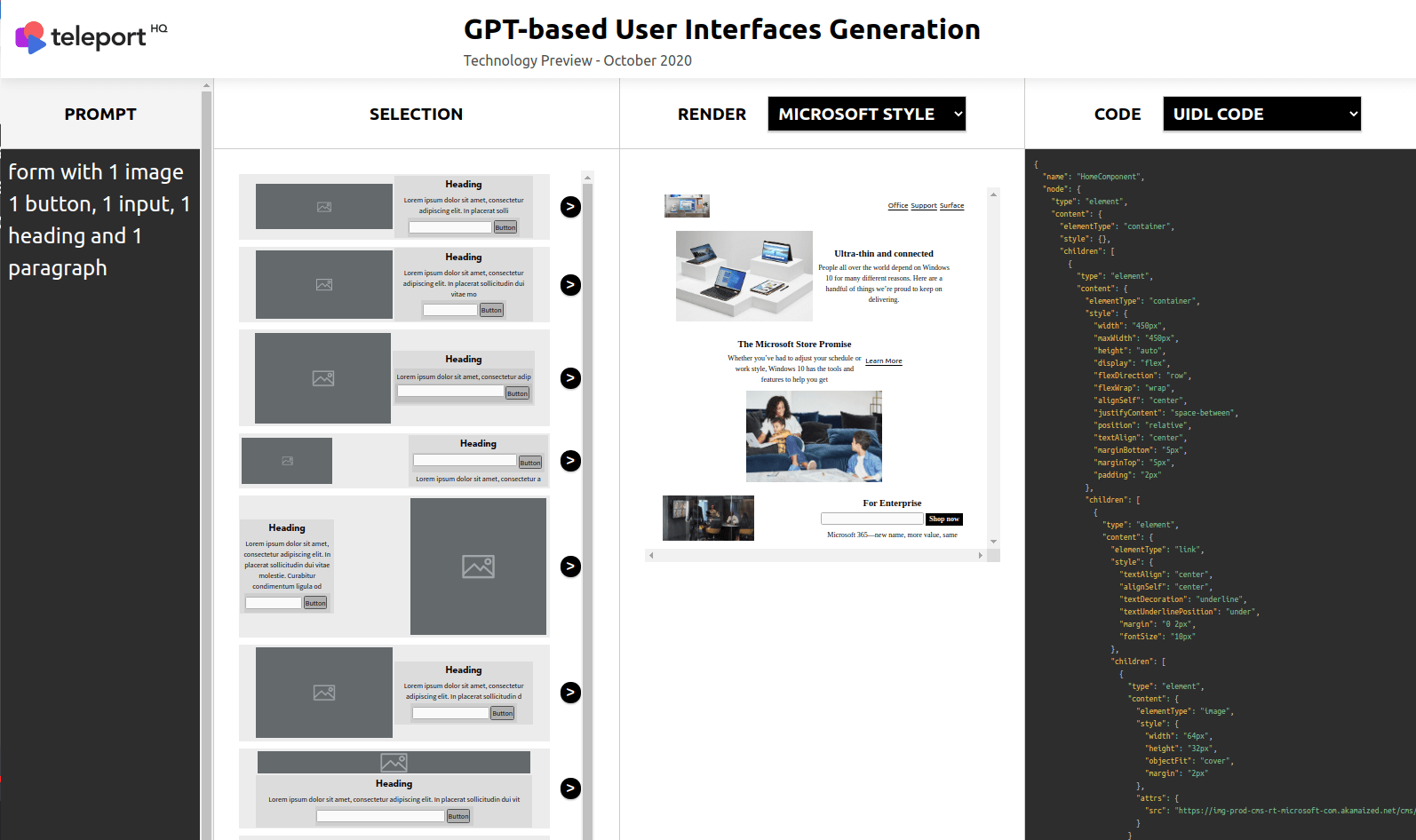
New Horizons: Heading into 2021…
Four years ago, TeleportHQ was one of the few teams who believed that building user interfaces by using natural language was possible. Since then, we have worked consistently to lay the building bricks on the path towards human-machine fluency. Our results bring us ever-closer to our original mission : to fully automate the process of building user interfaces.
Today, we have a fully-functioning GPT-UI prototype model. It contains 6 million parameters, which is in contrast with the 175 billion parameters of the titanic GPT-3.
But while GPT-3 is prized for its incredible strength due to its capability to handle potentially any english language task, our model offers more specialization and reactivity given its smaller, more agile size.
Over time, with the right data and thanks to the rest of the teleport architecture training, our GPT-UI could compete with GPT-3 on building user interfaces from natural language, with the added advantages of being fully customizable while using just a fraction of the resources needed to run the model.
TeleportHQ has already started to use the same approach in order to create other new models specialized in creating specific components and full mobile designs.
We are enthusiastic about its potential, and confident that in the near future we will be able to generate full, high-fidelity web-pages with a single request.
If you would like to request a private demo, propose a collaboration, or give us feedback, we invite you to contact us at hello@teleporthq.io .
