
What Is Web Scraping and Why Do We Need It
Web scraping is a technique employed to extract the underlying data of a web page. This data is generally composed of the HTML/CSS/Javascript text files and other assets such as the referenced images, videos, and fonts which are used by a browser to render that specific web page. The collected data is then stored into files or into a database for further processing.
At TeleportHQ, we’re continuously researching ways of improving our code-generation capabilities from wireframes or high-definition designs. Since there is a lot of ML involved in this process, we need significant amounts of curated data to work with. While the RICO dataset was good enough to get us started with native mobile pages, we felt that we would benefit from putting the effort into building our own web pages dataset for several reasons:
- There are hardly any public datasets that meet our quality requirements
- Control over the data - we can specify exactly what information we need to fetch from the websites
- Scaling - as the research advances we are going to need more and more data
- Organization and accessibility - providing a fast and simple way to access the data
How Is It Done?
Web scraping a web page involves 2 steps: fetching it and extracting from it. Fetching is the downloading of a page, meaning the initial HTML string and all the referenced assets, which is exactly what a browser does when you view the page. Therefore, web crawling is a main component of web scraping: we fetch pages for later processing. In our case, the crawling is done using Puppeteer, a Node library that provides a high-level API to control Chrome or Chromium. By launching a headless Chromium, we are able to fetch a webpage and use it for retrieving the data.
There are many ways for extracting data from a website but for our case, we are using a technique called DOM parsing. When a web page is loaded, the browser creates a Document Object Model of the page which is then used for the rendering on the screen. The HTML DOM model is constructed as a tree of Objects which can be parsed to retrieve the required information.
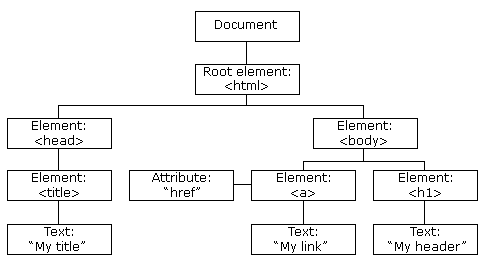
For each element in the DOM, we are retrieving a list of attributes that provide information about size, position, color and much more.
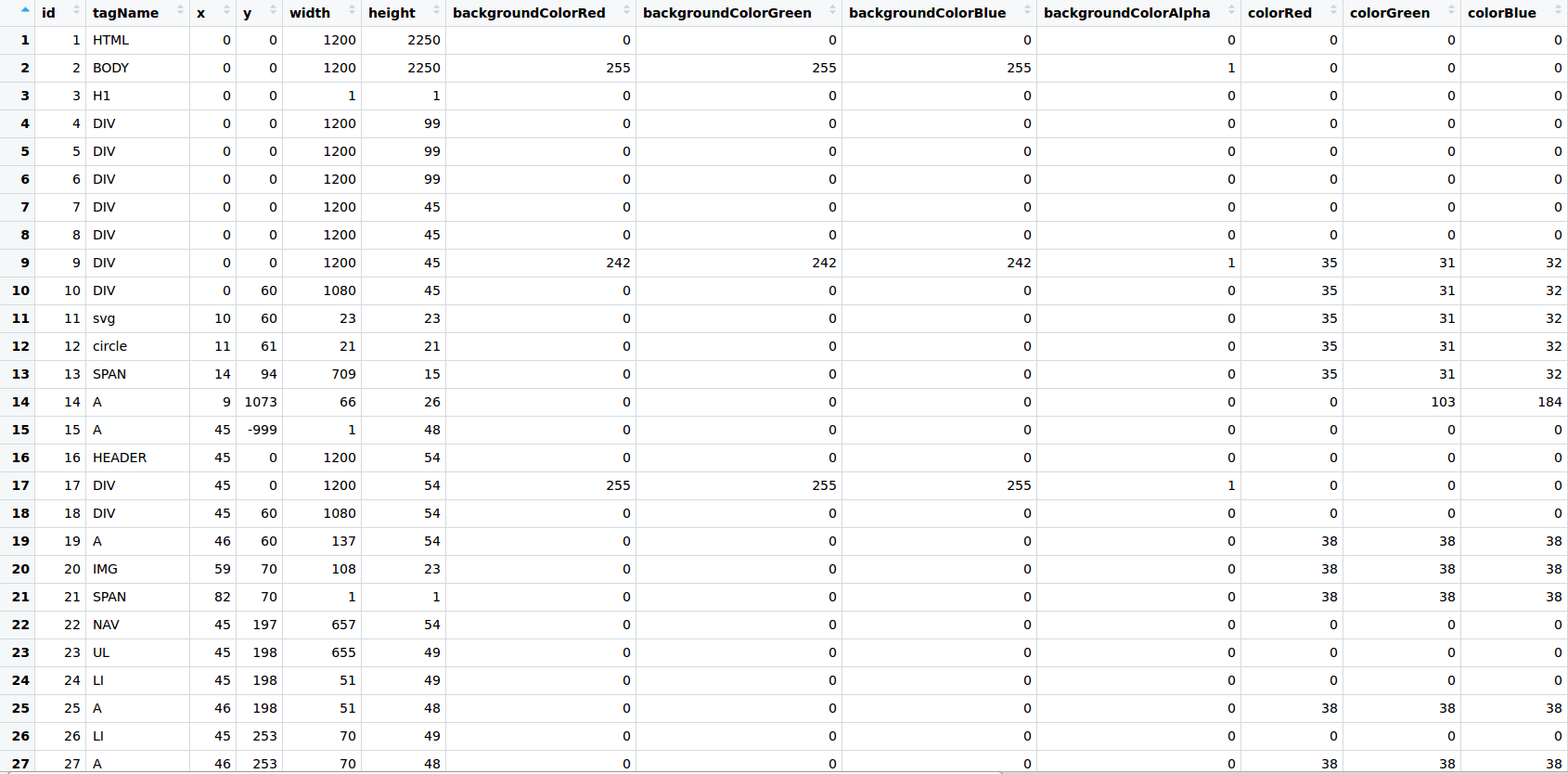
First Problems
After working with the Websites Dataset, we have noticed that a lot of websites inside were causing problems such as box overlapping or 404 pages.

The box overlapping was caused by invisible or out-of-viewport elements that are loaded in the DOM but are not displayed until a certain event. We are not saying that these sites have a bad design, but they would be causing inconsistencies when training an ML model. The 404 appeared because the browser was able to communicate with the server, but the server could not find what was requested. The DOM of the 404 page is still loaded and the page is parsed, but no useful information can be extracted from there.
Ml Classifier to the Rescue
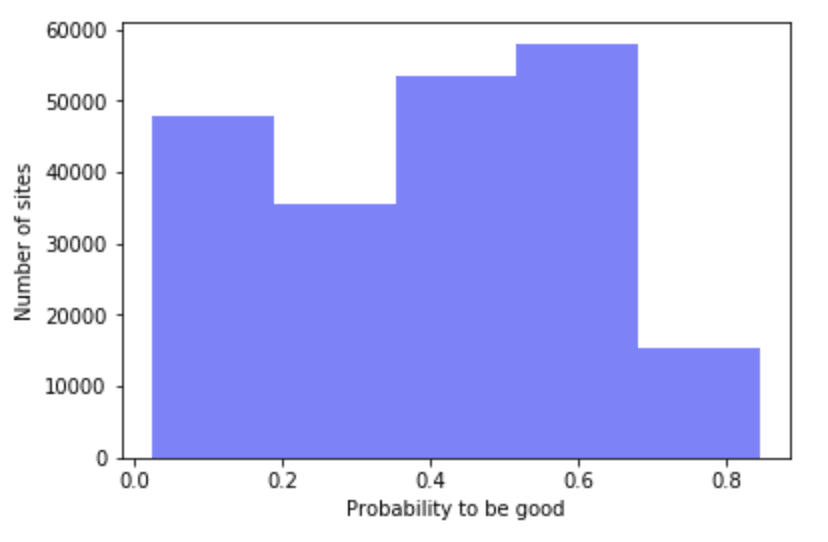
The solution we found to solve these problems was to create an ML classifier that gives us a probability of that website being good for use. We started by manually annotating websites into different categories, from an objective point of view, by following some criteria such as: “Are the boxes overlapped?” or “Does the page have enough information?”. To make the process easier, we made a custom web application using R shiny with a specific visualization to annotate data point one by one.
The annotations were then used as training data for our XGBoost model and, after testing it, we obtained 85% accuracy. For deployment, we used SageMaker, mainly because the XGBoost library was too big to be enclosed into a Lambda container.
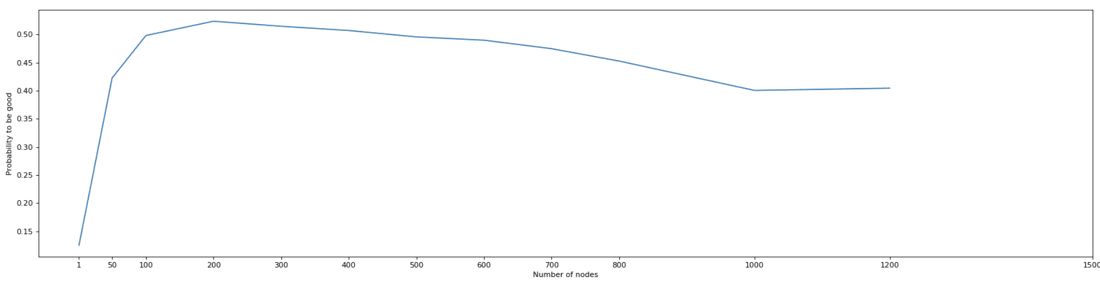
Scaling
The first version of the Web Scraper was a Node.js application that used asynchronous calls to parallelize the parsing process. It was a good start and it allowed us to quickly parse our first websites. However, when we tried to parallelize work, we quickly ran into the hardware limitations of our local computer. RAM got quickly exhausted and our CPU couldn’t handle it. In order to increase the processing power, we decided to move the parser to an m4.4xlarge EC2 instance on AWS that featured 16 vCPU and 64 GB of RAM. This has been done only to increase the parsing speed
The main downside of this approach was that everything had to be done manually. The input of the websites, the feature engineering, the ML inference, the upload on S3 after everything is done and not only. A solution to this problem was to create a pipeline that would do all these things automatically and organize them to improve accessibility. Moreover, AWS Lambdas support a large number of concurrent functions that would allow us to parse more websites/minute.
Pipeline Structure
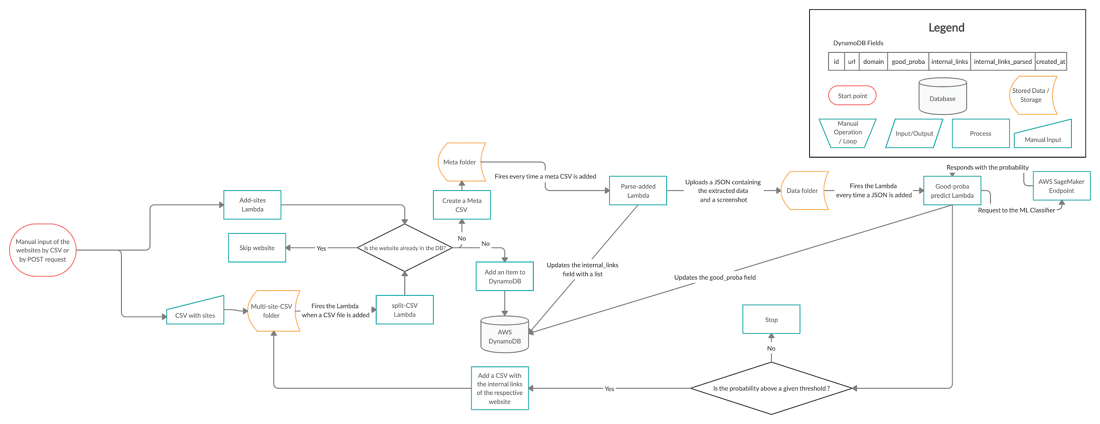
The pipeline contains 2 types of elements: processors and storage. The processors are Lambda Functions that are triggered by certain events, and as storage, we have the DynamoDB NoSQL Database and an S3 bucket. The DynamoDB contains high-level information about the websites like domain, page, or the time at which the website was parsed. The S3 bucket is structured in 3 folders:
- Multi-site-CSV - contains CSVs with multiple websites to be parsed
- Meta - contains information about one website needed for the parsing
- Data - contains the output of the parser: one screenshot and one JSON containing all the information extracted from the DOM
Starting Point
In order to start the process, we need to input one or more websites. We have two ways of doing that. One way would be accessing an endpoint with the URL as a request parameter. This will only parse the given website and return as a response, its name in the S3. The second way is to upload a CSV in the ‘multi-site-CSV’ folder with all the websites to be parsed.
Lambda Triggers
There are 3 Lambda Functions inside the pipeline that are spinning the wheels.
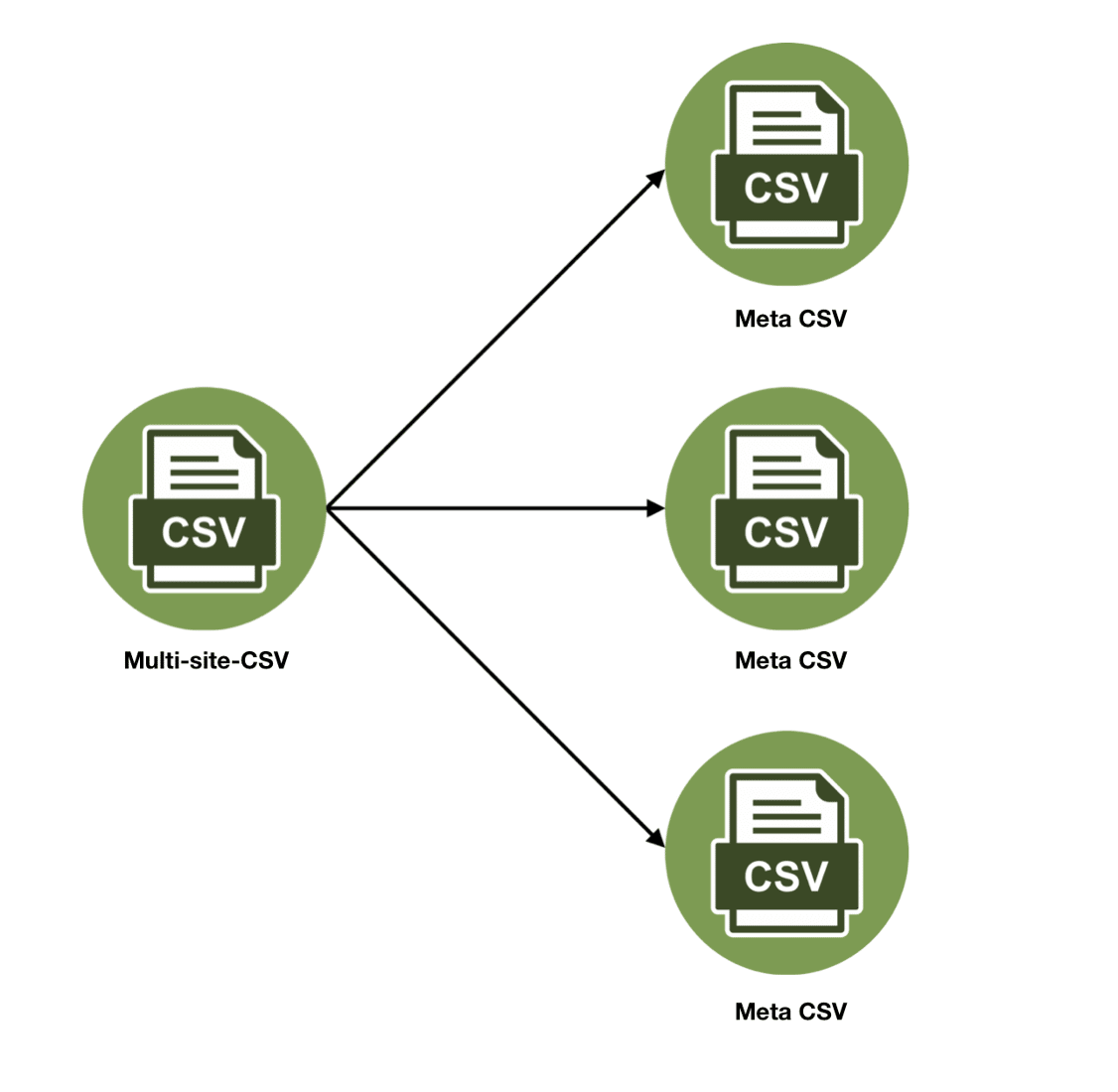
The first Lambda is the ‘CSV-split’ function that is triggered every time a CSV is uploaded in the ‘multi-site-CSV’ folder. It splits the big CSV into smaller CSVs that contain information about one website and uploads them to the ‘meta’ folder in S3.
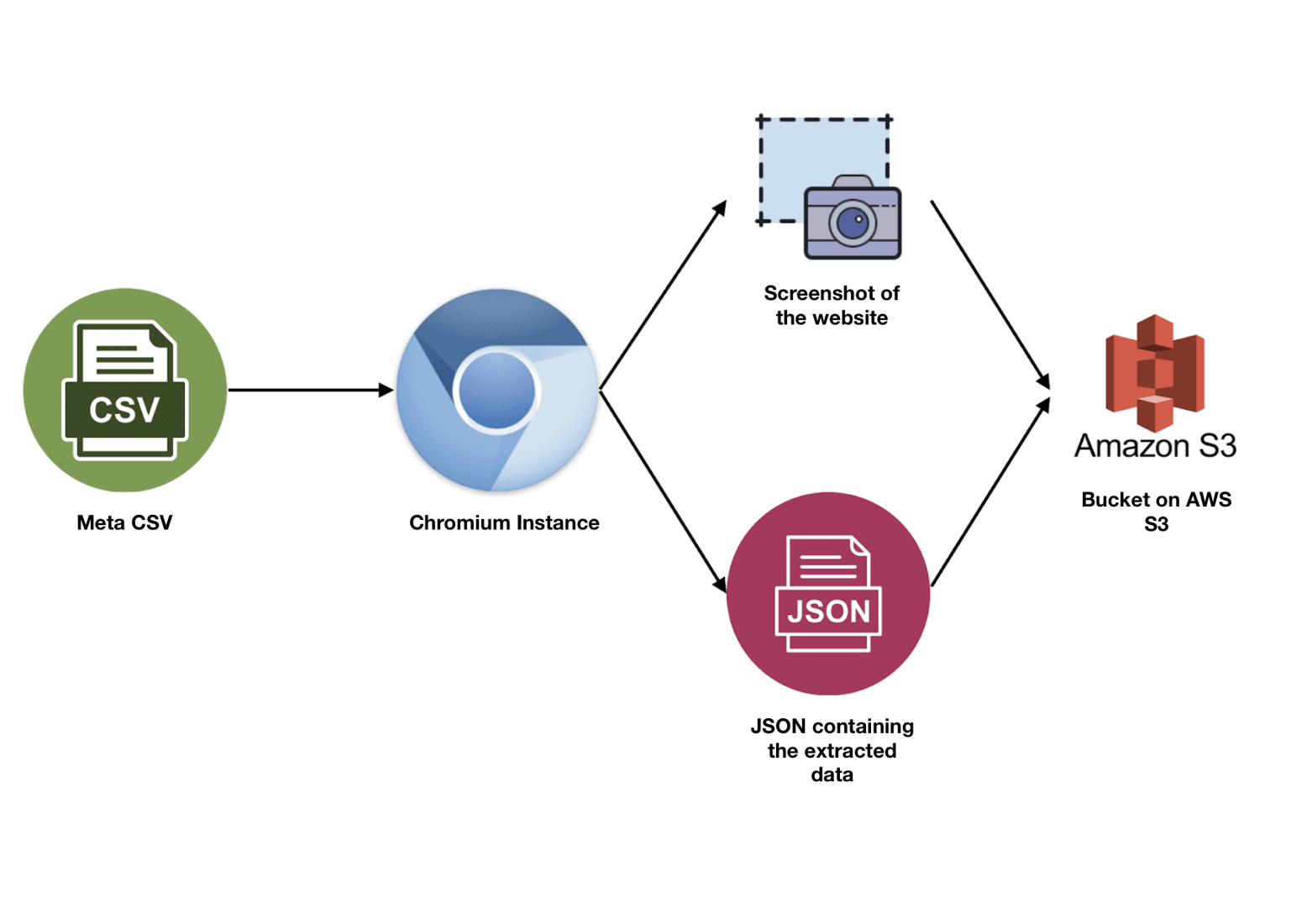
The second Lambda is the bread and butter of the pipeline, the ‘parse-added’ function. This Lambda contains the parser and is the most expensive resource-wise. It is triggered at every new CSV upload into the ‘meta’ folder and parses the respective website. If the parsing succeeds it returns a screenshot, a JSON, and a list of internal links that will be used later in the pipeline for recursive parsing. It then updates the DB for the respective website and uploads the 2 files to the ‘data’ folder in the S3 bucket. If the parsing fails, the S3 and DB items are deleted to avoid inconsistencies.
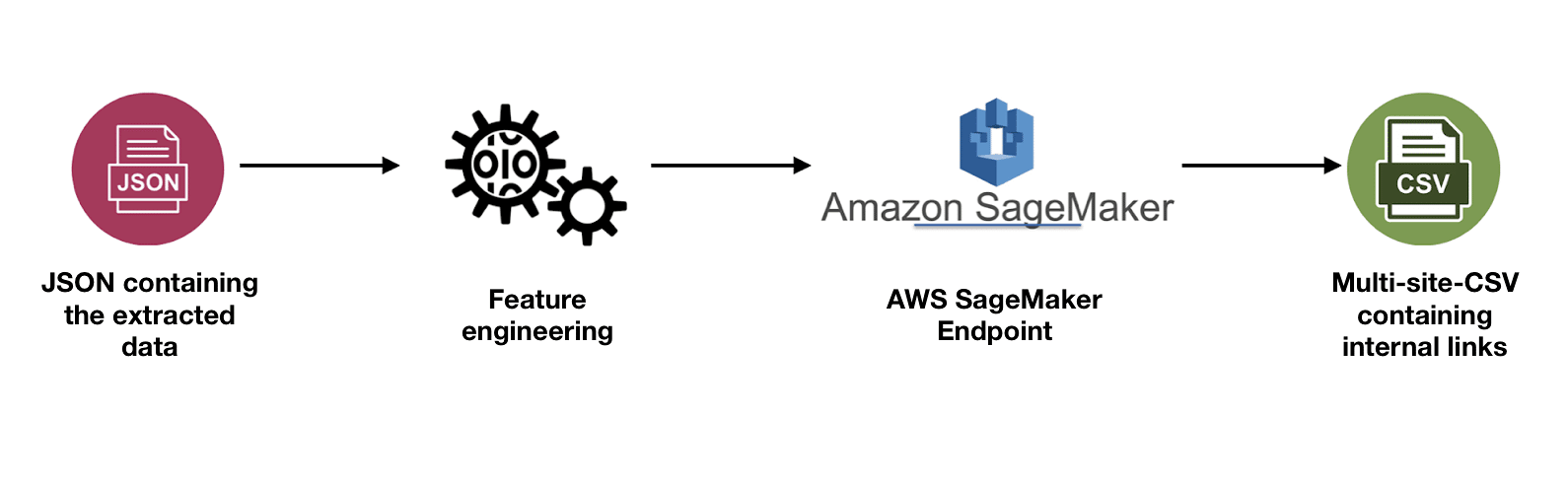
The third and final Lambda function contains the ML part of the pipeline. It takes as a trigger each uploaded JSON of the ‘data’ folder and uses the data inside the JSON to conduct the feature engineering. It then fires a request with the features to the SageMaker endpoint which will return a probability of the website being good. If the probability is high enough, it uploads a CSV with all the internal links of the respective website to the ‘multi-site-CSV’. The upload triggers the first Lambda and so, a loop is formed.
Results
Performance
The performance has seen a massive improvement over the time of development. The Node.js application had an average parsing speed of 20 websites/minute. After moving to EC2, along with some other optimizations, we managed to bring the parsing speed up to 240 websites/minute. However, this is nothing compared to the 4500 websites/minute that we have obtained using AWS Lambdas.
What can we do with the data?
One of the paths that we chose to pursue is Object Detection on Web Screenshots. The information that we have extracted from the websites provided us with everything we needed to get started.

What we are trying to achieve is a high-fidelity detection of the elements in a web page. We are using the coordinates of each element (top, left, width and height) to compute the corresponding boxes and then use them to train the ML model. The data extracted from the DOM for the above example was inconsistent and thus, invisible elements appear or, on the other hand, elements are not detected. Because we used qualitative websites for the training, the model was able to infer even the location of those elements (the paragraph with the background image on the upper side of the page) and ignore the invisible ones (the elements on the left side).
At first, we categorized every element into either text or image, but as the development advances, we will proceed to other HTML tags such as tables, lists or inputs.
Conclusions
The number of publicly available and curated web datasets is very low, and the few available have a limited number of data points. This groundwork has enabled us to become independent and to precisely control the quality and quantity of our data. Furthermore, an important added benefit is that it allows us to dynamically rebuild - in just a few hours - new updated and improved datasets. If you are a researcher and would like to have access to our data, please feel free to drop us a line.
During the building process, we’ve also learned a lot about our industry and the underlying technologies. This knowledge has given us a lot more context about how we should focus our research about automating the process of user interface building.
As always, we’re extremely interested in exchanging with other enthusiasts regarding this topic. If you’re interested in our work, please feel free to contact us through any of our social media channels found in the footer of this website.
