
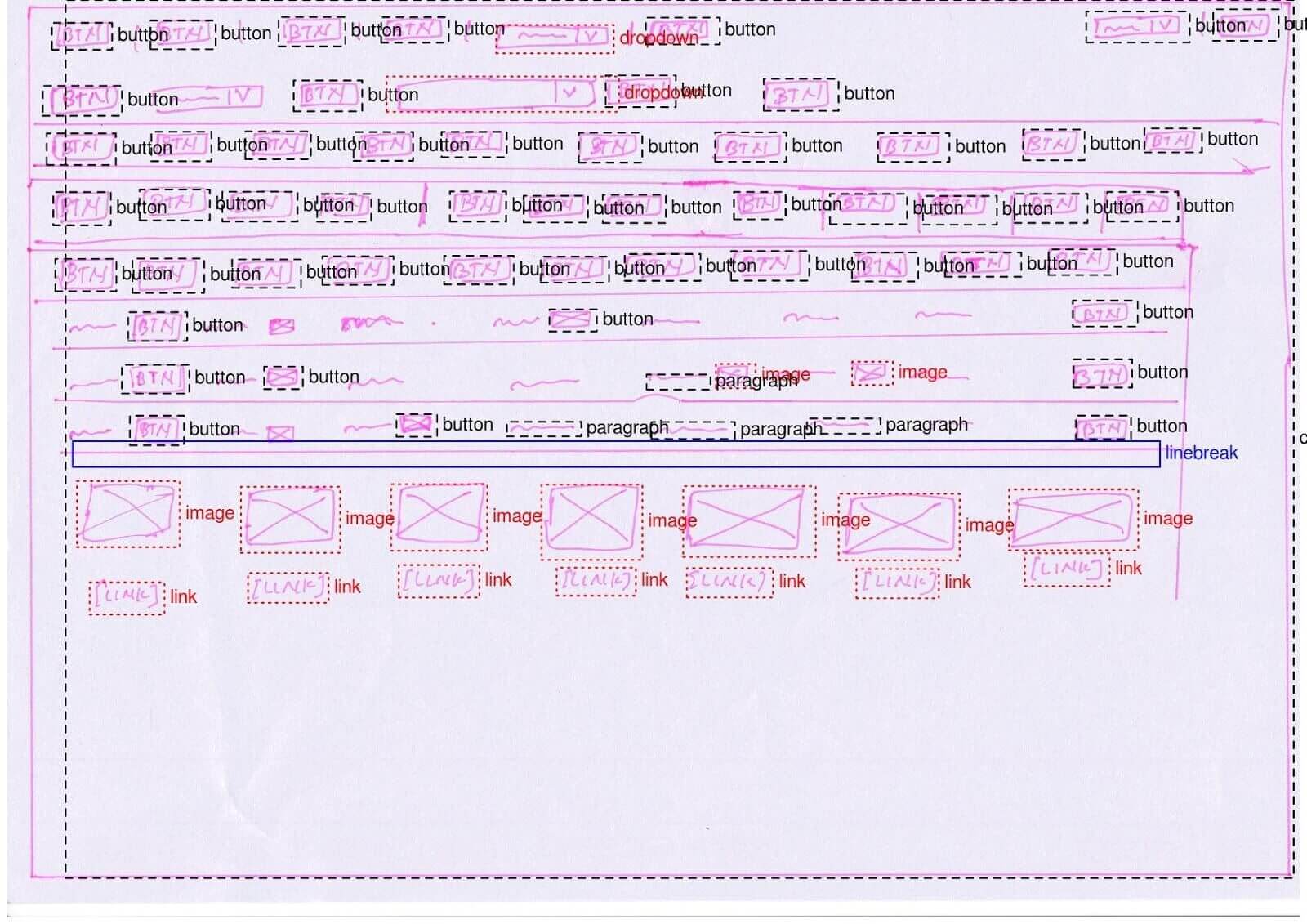
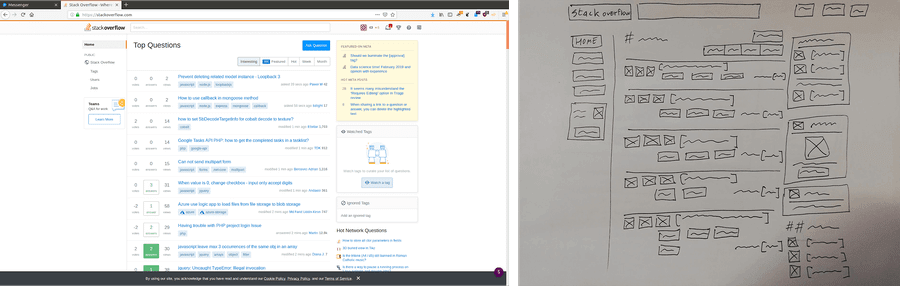
A few months ago, we introduced new conventions to facilitate the creation of a machine learning model that could interpret hand drawn wireframes. We wanted to decrease ambiguity for the human in charge of annotating each image needed to train the machine learning model.
New Dataset
The resulting artifact is a guideline document we recommend to all of our API users in order to make the most of the technology.
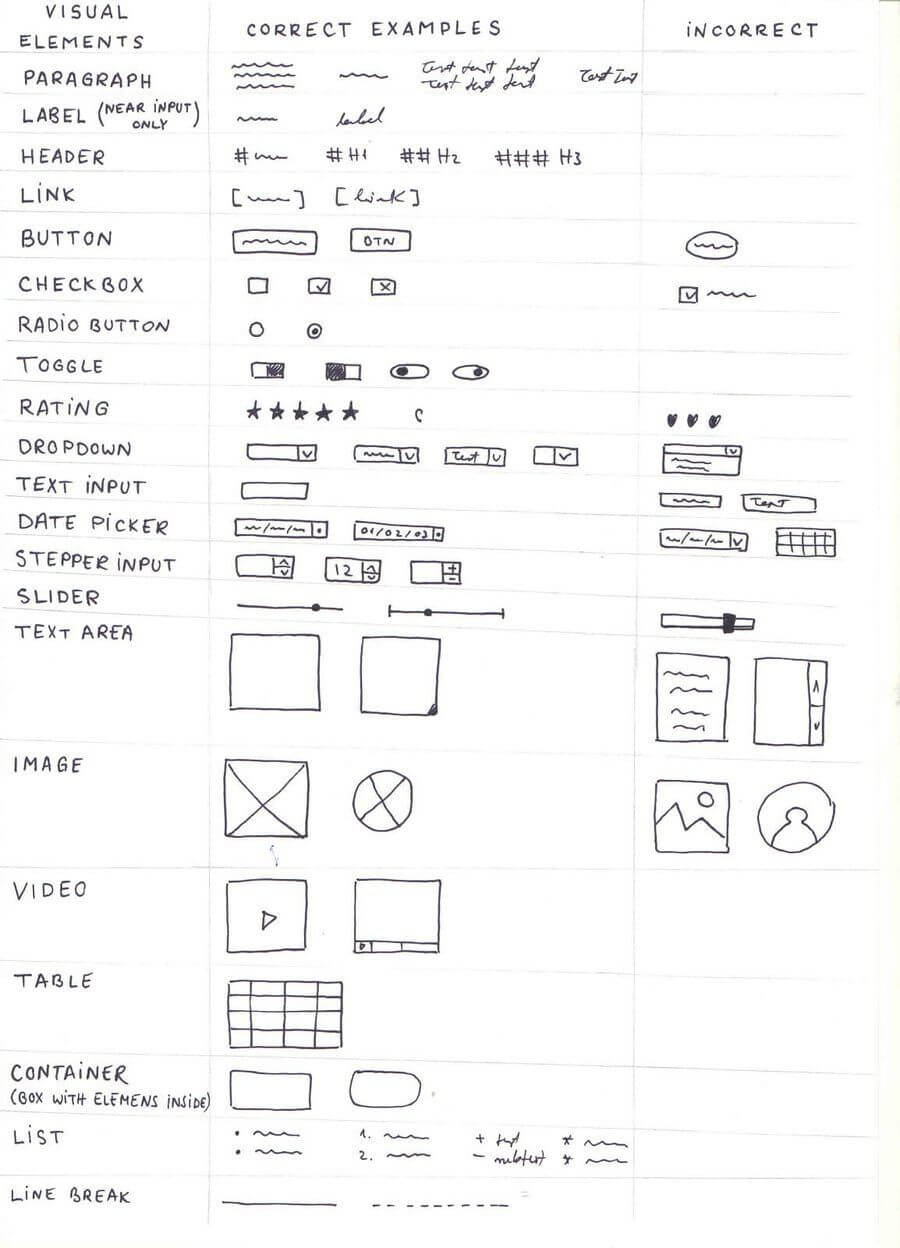
Once we understood what kind of data we were looking for, we started the momentous task of collecting enough data to train our model.
Along with this effort, we had to balance two important conditions in machine learning, i.e. bias and variance. On one hand, we needed guidelines to narrow in on something manageable for the model to learn (thus we reduced the annotation bias). On the other hand, we still needed a variety of images, drawn by different people, in different colors etc... (we wanted a heterogeneous dataset). However, new images will be biased if the initial guidelines are not followed and thus, wrongfully predicted.
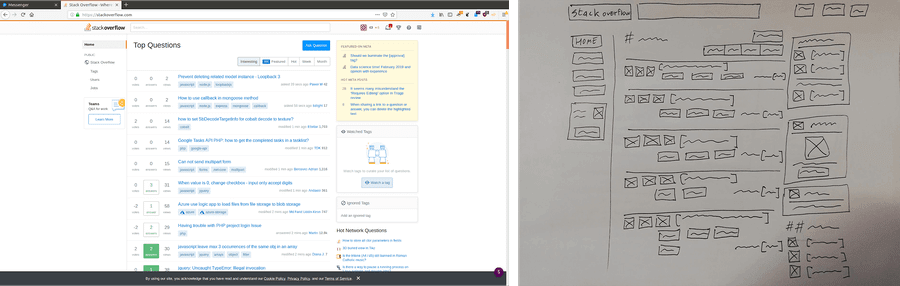
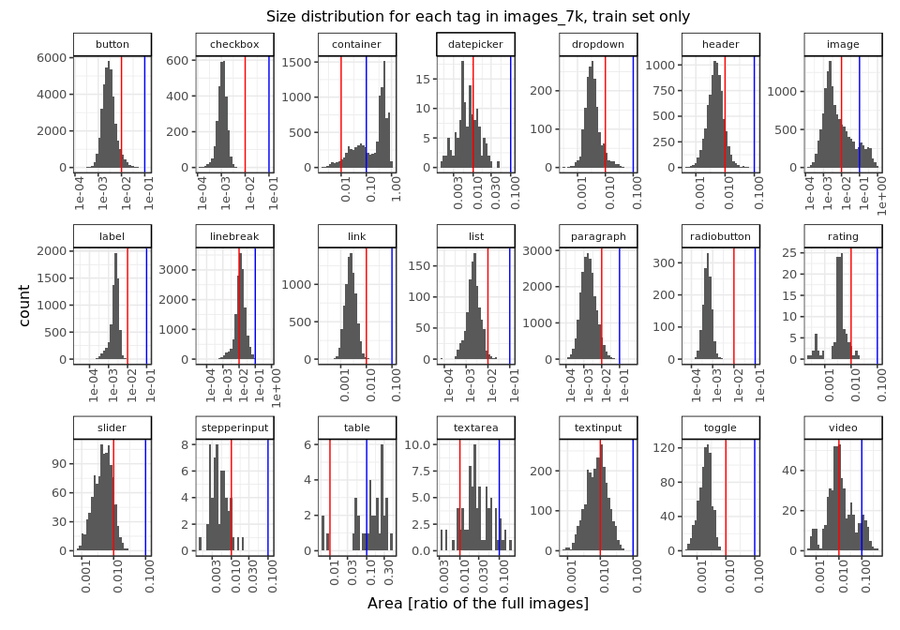
An important consideration in training machine learning models is the validity of the dataset (each class should be evenly represented, whenever possible). In studying the annotations in our dataset, we found that some classes are underrepresented, making it more difficult for the model to detect (table, rating, list, text area, stepper input). When carrying out the analysis, we also examined the size distribution for each element, a crucial characteristic in object detection datasets. Some elements are smaller, like links and radio buttons, and naturally these are harder to detect, while bigger elements, such as a container or an image, are easier to detect.
Results
It’s difficult to predict when we’ll have collected enough images for our model. It’s clear, however, that the quality of the model will increase proportionally with the amount of images used for training. Because we consider the data collected so far to be sufficient for preliminary models, we decided to begin training before finalizing the first step in the data collection process.
To evaluate our models, we used the mean average precision with an intersection over union or 50% (mAP@IOU 0.5) - you can find more information here. Using this metric, the performance for the first version of the API was 40%. In December, we released a version with 55% accuracy using synthetic data to improve the model. The model released with the current version is at 85% on the test set. However, we suspect this number is optimistic so we’re also putting together a complementary test set with a different team.
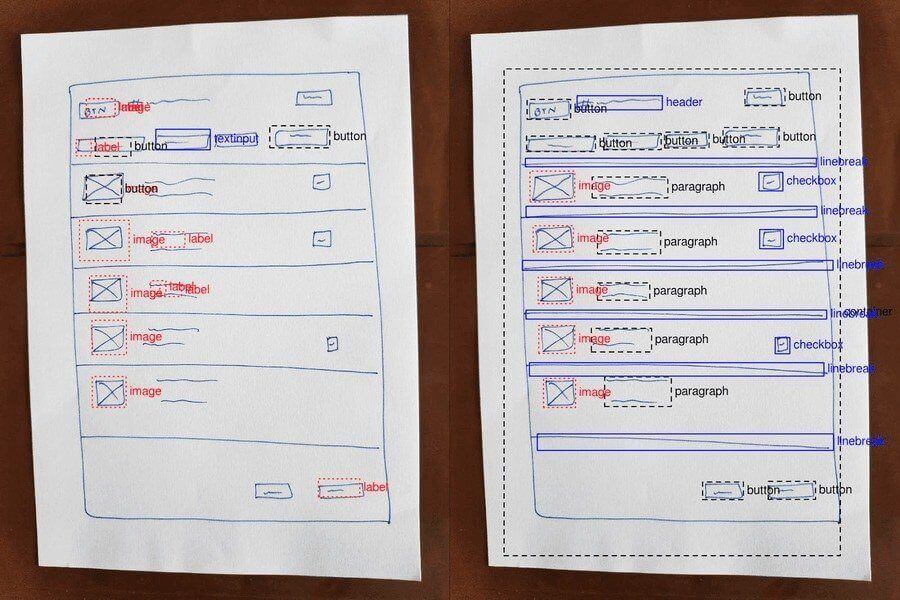
We still have work to do; the model has difficulty identifying wireframes containing many/multiple elements. Furthermore, the uneven dataset poses additional complexity when uncommon classes are used, such as sliders and ratings.
Machine Learning for Enhancement Not Replacement
As is often the case where artificial intelligence and machine learning are involved, the eventual result is a symbiotic relationship between the two entities instead of a replacement of the human by the machine. By the same token, this emerging technology requires a good deal of trial and error by the end user to capitalize on its promise.
As is often the case where artificial intelligence and machine learning are involved, the eventual result is a symbiotic relationship between the two entities instead of a replacement of the human by the machine. By the same token, this emerging technology requires a good deal of trial and error by the end user to capitalize on its promise.

