
Many great ideas start on a piece of paper or a whiteboard. Why? Because hand-drawing is still the most natural, intuitive, and efficient way of structuring abstract or visual thoughts. Humans, despite their efforts to adapt to the digital world, still often perform better in analogical situations.
With this observation in mind, we decided to focus on one specific use case: automate the generation of production-ready code from hand-drawn wireframes, and at this stage, we believe that having a digital proof of concept straight out of a shareholder meeting is not a distant dream anymore.
As explained in this previous article, we aim to use artificial intelligence (AI) and machine learning (ML) in different points of our platform. However, we know that ML cannot solve every problem, at least for now. Our vision API is part of a bigger ecosystem and it ‘only’ takes care of detection bounding boxes. Those raw bounding boxes must then be converted into a User Interface Definition Language (UIDL) representation. Afterwards, our code generators - and some proprietary decision-making layers - can take over to generate the code.
Need for data
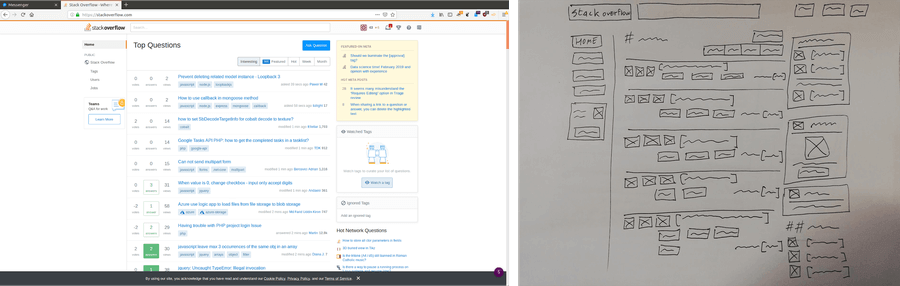
On paper, for a data scientist, the problem looks very simple: we have pictures or scans of wireframes that are annotated so that we know where elements like images, buttons, and texts are. Looks easy, so let’s just go online and collect some images and we’ll annotate them later.
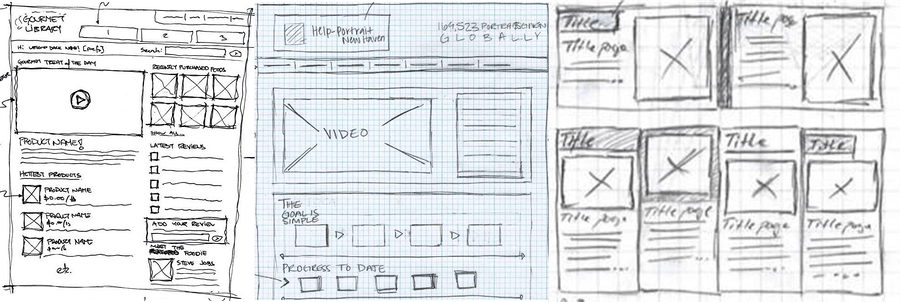
To get started, we decided to harvest free data from the web. This was good enough to get a rough idea about the nature of the data we were about to work with, but it also allowed us to realize that this source could not provide enough images to train an ML model. Then, we stumbled upon a second issue which was that nobody had the same conventions when drawing wireframes... As a matter of fact, later on in the process of collecting data, we learned that quite often there are specific guidelines inside each organization.
To solve these first issues, we decided to make our own guidelines and started drawing wireframes ourselves. Once every team member contributed, we decided to “friendsource” our data and went around to ask each of our (awesome!) friends to draw wireframes for us as well. This is definitely not a viable strategy at scale as friends come in very limited supply but it allowed us to have an initial coherent collection of hand-written wireframes.

We had the X but still needed the Y
The simplest intuition on machine learning is that the computer learns a function, by itself, to predict Y from X by looking at a large number of examples. At that point, we were a few hundred images rich, so we had the X. We knew this would be enough for a proof of concept so we went on to the next step: annotations to get the Y.
We started manually annotating each drawn wireframe to pinpoint where our images, buttons, and texts were placed. Useless to say that this task wasn’t the most pleasant part of this initiative, but nothing comes for free in this life, so we just bit the bullet.
In our case, the process was quite long. It was initiated by some random work with chatbots and conversational interfaces. At that time, in 2015, most of us were still working in the JavaScript depaThe good part is that it helped all our team members fully appreciate the real value of clean and structured data, a type of resource which is extremely scarce and a bottleneck for most data science projects. artment at Evozon. That work never got into production but we all remained in a state of excitement: it opened a lot of new perspectives about how we could build new user experiences.
Need for consistent data
Once we had the X and the Y, we could finally start the fun part: model training. This took way less time than the data collection and the conclusion was, of course, that we needed more data!
Nonetheless, it got us a proof of concept and a very good baseline for improvement. The accuracy of the model was 55% on our test set, meaning that 55% of the elements were correctly detected.
Apart from the low number of data points, this is when we realized that we’ll have to deal with a new challenge as we had a large number of collisions in the annotation. Some annotations were ambiguous, even for a human:
- Is it an image or a button?
- Is it a header or a paragraph?
- Is it a text input or a button?
In some cases, such as headers and paragraphs, the main structure of the wireframe could help the decision. But in many other cases, there was no way to tell the difference. And so, in turn, there was no way for the model to be correctly trained.

Need for stronger guidelines
Like with many engineering problems, the most difficult part is to get to a first solid baseline from which you can improve. Machine Learning is no exception. In our case, a solid baseline meant strong constraints on what and how the model could detect the user’s intent. Even if we plan to expand our capabilities in terms of element variety and in terms of drawing freedom later on, this is why, for now, we’ll limit ourselves to the following conventions (many inspired from markdown):
- Header: as it’s colliding with a paragraph we propose to prefix it with a hashtag
- Text input: as it’s colliding with the button element so we propose to use only an empty text input
- Link: we’ll surround it with square brackets
- Labels: will be detected as such only when associated with an input
- Paragraph: if the text is not a label, header or link, it’s a paragraph
- Image: can only be a rectangle or a circle with a cross inside
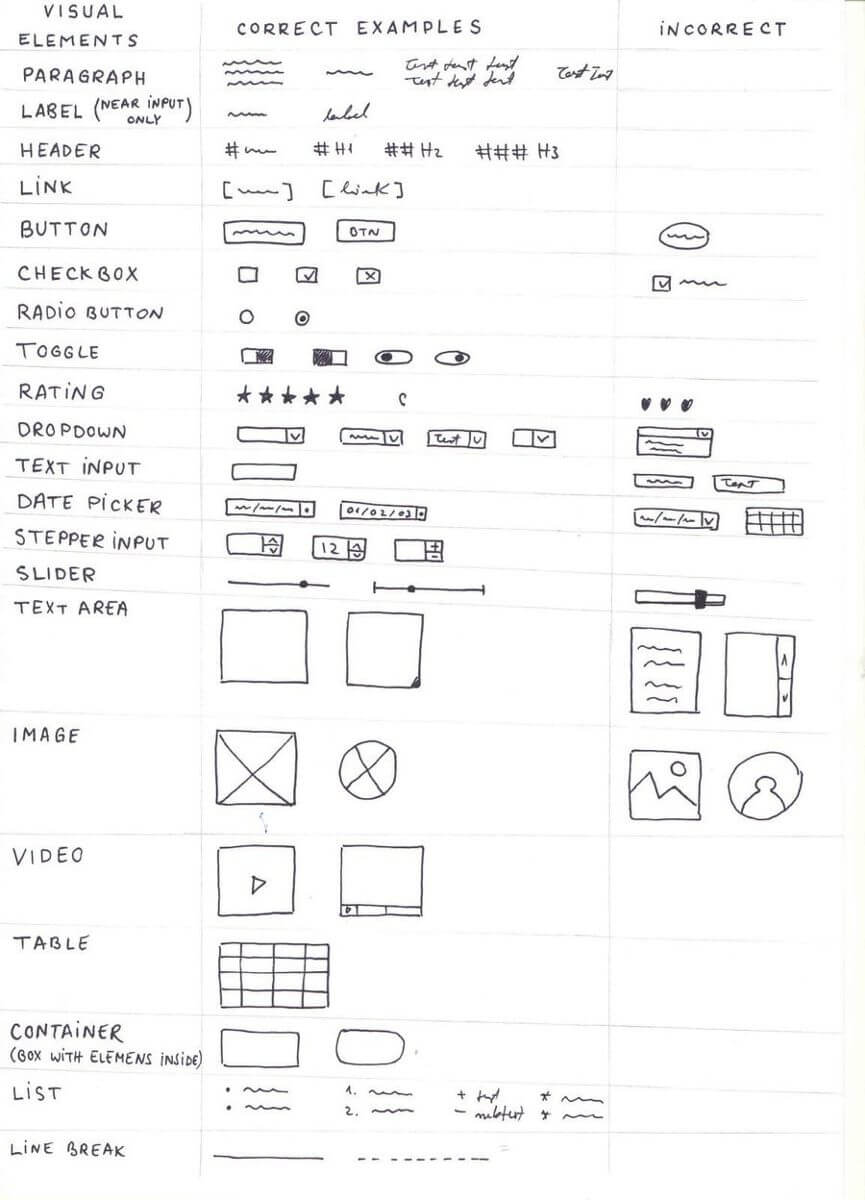
It was a hard decision to make but we strongly feel that the constraints we added will come with some important benefits which will overcome the limitations, such as:
- Is it a text input or a button?
- Is it an image or a button?
- Make the annotation unambiguous
Conclusion
For the moment, our vision API still follows the old guidelines but in our next version (coming soon), we’ll use the new ones. As always, we’d like to remind our readers that this is work in progress and it’s far from perfect but we’re eager for any feedback or ideas about how to make our Vision API better. Feel free to drop us a line on our Twitter account any time and follow us to check on our next updates.
